TensorFlow教程复习
复习一遍TensorFlow入门教程



将分tf2.0与tf1.0两大章节,分别重现TensorFlow教程中的关键章节。

import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
载入这个数据集后,会得到4个Ndarray:
-
train_images和train_labels数组是训练集 -- 即模型用于学习的数据 - 使用
test_images和test_labels测试集测试模型。
图像是28x28的ndarray,每一个像素的范围都是0,255。标签是一个整形数组,范围为0到9,与图像表征的衣服类型一一对应。
每一幅图像被映射到单个标签上。由于类名不包含于数据集,我们先把类名列出来以待后续使用。
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
训练模型前我们先检查下数据集的格式。以下结果说明训练集中共0.6billion张图片,每幅图片由28*28个像素组成:
train_images.shape
# 训练集中有60000个标签
len(train_labels)
# 每个标签都是0到9之间的整数
train_labels
# 测试集中有10000张图片,每一幅图也是28*28像素
test_images.shape
# 测试集包含10000个标签
len(test_labels)
在将数据送入网络前,必须对其进行预处理。如果你查看训练集中的第一幅图片,你会发现像素值在0到255之间:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()

在将值送入神经网络模型前,有必要将他们缩放到0到1之间。为了做这个操作,直接将值除255即可。训练和测试集必须以同种方式处理:
train_images = train_images / 255.0
test_images = test_images / 255.0
为了验证数据是正确格式,且你已经准备好训练和构建网络,我们绘制前43幅图片,并在图片下方显示其类名:
plt.figure(figsize=(10,10))
for i in range(43):
plt.subplot(9,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap = plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

model = keras.Sequential([
keras.layers.Flatten(input_shape=(28,28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])
网络中的第一层,tf.keras.layers.Flatten将图片格式从2维数组转化为1维数组(784个像素)。可以想象它是拆分开像素的各行,再将它们连接起来。这一层没什么特别的参数要学习,它只是重新格式化数据。
在像素被压平之后,网络随即连接两个tf.keras.layers.Dense层。这些是紧密连接(或者称作全连接)的神经网络层。第一个Dense层有128个节点或者神经元。第二个(输出层)返回一个长度维10的序列,每个值都表示当前图片属于该类别的概率。
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=10)
随着模型训练,损失和进度指标不断更新,模型最终在训练集达到了91%的精度。
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
probability_model = tf.keras.Sequential([model, tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
# 模型对所有测试集中的图片预测了类别,我们看看第一个预测的结果:
predictions[0]
模型预测的类别是一个长度为10的数组。它们表征了模型给图片分属于10个类的“置信度”评价。可以用以下方式知道哪个标签有最大的置信度:
np.argmax(predictions[0])
# 所以模型认为图片最可能对应一个ankle boot靴子,或者class_names[9].
# 我们检查一下测试集标签,来证明模型的看法是对的:
test_labels[0]
绘制图片来看看所有的预测结果:
def plot_images(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}%({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label],
color=color))
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color='#777777')
plt.ylim([0,1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_images(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i,predictions[i], test_labels)
plt.show()

i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_images(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i,predictions[i], test_labels)
plt.show()

绘制一些图片和它们的预测结果就会发现,即便模型置信度很高,也可能是错误结果。
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=[2*2*num_cols, 2*num_rows])
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_images(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i,predictions[i], test_labels)
plt.tight_layout()
plt.show()

img = test_images[142]
plt.imshow(img)

tf.keras模型已经经过优化,们可以对一个“batch”或者几何进行预测。所以即使你只是用单张图片,你也需要将它添加到列表中:
img = (np.expand_dims(img, 0))
print(img.shape)
# 现在对图片的正确标签进行预测:
predictions_single = probability_model.predict(img)
print(predictions_single)
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=30)

# keras.model.predict 返回一个二维数组,其中每个一维数组都对应
# batch中的一个图片。通过以下方式拿到我们对该批中唯一一幅图片的
# 预测结果:
np.argmax(predictions_single[0])
from __future__ import \
absolute_import, division, \
print_function, unicode_literals
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print("GPU is", "available" if tf.config.experimental.list_physical_devices("GPU") else "NOT AVAILABLE")
dir(tfds.Split.TRAIN)
?tfds.Split.TRAIN.subsplit
# 将训练集按照 6:4 的比例进行切割,从而最终我们将得到 15,000
# 个训练样本, 10,000 个验证样本以及 25,000 个测试样本
train_data, validation_data, test_data = tfds.load(
name="imdb_reviews",
split=['train[:60%]', 'train[60%:]', tfds.Split.TEST],
as_supervised=True)
train_examples_batch, train_labels_batch = next(iter(train_data.batch(10)))
train_examples_batch
train_labels_batch
embedding = "https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1"
hub_layer = hub.KerasLayer(embedding, input_shape=[],
dtype=tf.string, trainable=True)
# 注意这里直接以函数形式调用hub_layer即可得到输出
hub_layer(train_examples_batch[:3])
model = tf.keras.Sequential()
model.add(hub_layer)
model.add(tf.keras.layers.Dense(16, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_data.shuffle(10000).batch(512),
epochs=20,
validation_data=validation_data.batch(512),
verbose=1)
results = model.evaluate(test_data.batch(512), verbose=2)
for name, value in zip(model.metrics_names, results):
print("%s: %.3f" % (name, value))
电影评论文本分类
已有中文版本,此处仅列出代码:
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
from tensorflow import keras
import numpy as np
print(tf.__version__)
imdb = keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels)))
print(train_data[0])
print(train_labels[0])
# 一个映射单词到整数索引的词典
word_index = imdb.get_word_index()
# 保留第一个索引
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # unknown
word_index["<UNUSED>"] = 3
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
decode_review(train_data[0])
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
?keras.preprocessing.sequence.pad_sequences
len(train_data[0]), len(train_data[1])
print(train_data[0])
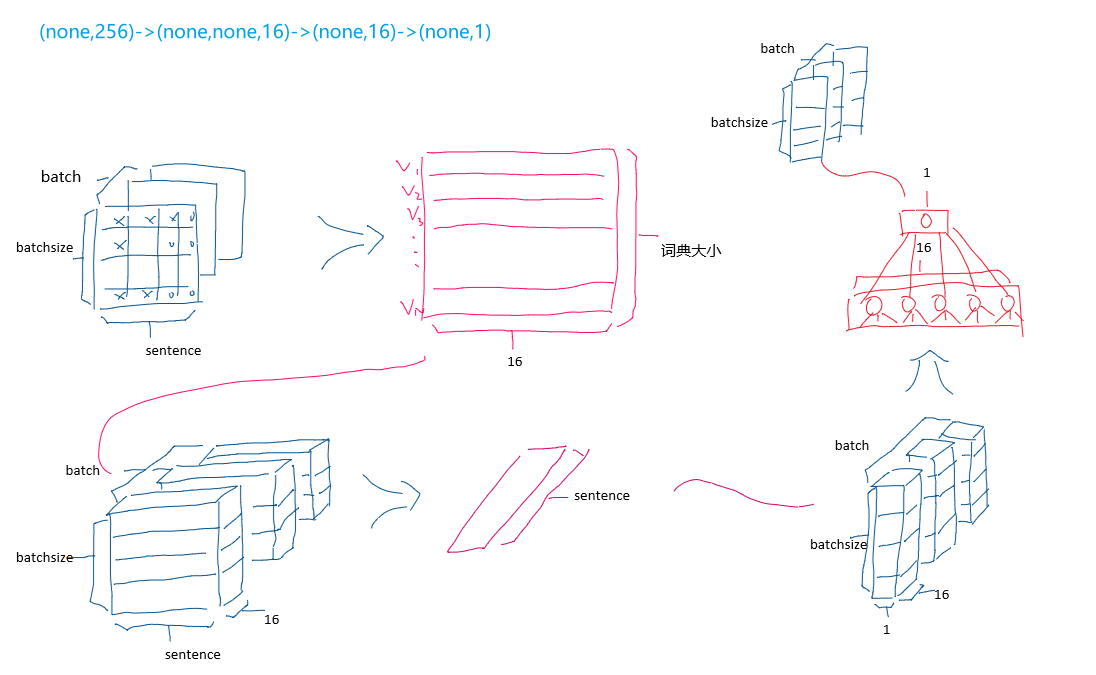
# 输入形状是用于电影评论的词汇数目(10,000 词)
vocab_size = 10000
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, 16))
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
x_val = train_data[:10000]
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]
history = model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
results = model.evaluate(test_data, test_labels, verbose=2)
print(results)
history_dict = history.history
history_dict.keys()
import matplotlib.pyplot as plt
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# “bo”代表 "蓝点"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b代表“蓝色实线”
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()

plt.clf() # 清除数字
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
